継続を使ったambの実装
ambの実装であるが、これが妙に難しい。なぜか?
- 継続の説明がない。継続を利用してamb を実装している。しかし、継続自体の説明はない。
- 継続の実装方法の説明がない。ambの実装とともにいつのまにか継続の実装も終了している。
- 最大の原因は、amb評価器のソースがスパゲッティになっているから! (高度なテクニックとかではなく、単にスパゲッティソースになっている。かなり酷い。)
なので、本文に入る前に①継続とは何か、および②継続の実装方法について自力で見通しをつけておかなければならない。
③スパゲッティなソースは、根性で読むのみ!(若しくは、一切読まないのも可)。
スパゲッティの中でも、analyze-application の動作が極めてややこしい。これだけ順を追って追いかけてみる。(analyze-amb より analyze-application の方が酷いスパゲッティになっている。)
あと注意は、amb評価器は、メタ関数とリスト処理だけで継続を実装している。スタックの操作や、call/cc の登場を期待して読むとちょっとあてが外れる。(なお、call/cc を使ったほうがよっぽどわかりやすいソースになるらしい‥・)
【1】
①継続とは何か。
ある処理の継続とは、その処理より未来の処理とその時の環境すべてのことである。
こう言われると、何がなんやらわからない。未来の処理とはなにか、PCの電源OFFまでのことか?10年後までの処理を含むのか?すべての環境とはなにか、PCのメモリのすべてのことか?、PCの現在時刻も含むのか?LANアドレスも含むのか?
なので、もう少し具体的な、コーディングできそうな定義が欲しい。
(1) 未来の処理とは?
合成関数を考える。
F(1) = w(z(y(1)))
合成関数中の各要素の未来の処理とはそれぞれ
1の未来の処理 → w・z・y yの未来の処理 → w・z zの未来の処理 → w
である。未来の処理のことを継続処理という。
1の継続処理 → w・z・y yの継続処理 → w・z zの継続処理 → w
である。以上で継続(処理)の定義終了である。
各継続処理を1列に並べてみると
1 → w・z・y、y → w・z、z → w
右からとなり同士をくっつけていくと
1 → y → z → w
という継続処理の列が得られる。こうして見ると、継続というのは単なる処理の実行順であり、フローチャートと同じである。
この図を元に、もう一度 1の継続処理を考える。
1 → (y → z → w)
と書くことができる。(y → z → w)という処理は、ようするに合成関数 w・z・y のことである。
同様に、yの継続処理は
y → (z → w)
と書ける。(z → w) は合成関数 w・z のことである。
この手順は繰り返すことができる。つまり、継続を2つづつ合成して、全体を1つの合成関数に まとめることができる。
(1 → (y → (z → w)))
こんな感じ。
もっと複雑な場合 v(z(y(1 2)),w(3))でも同じことができる。継続処理の列
1 → 2 → y → z → 3 → w → v
を2つづつまとめて
(((((1 → 2) → y) → z) → (3 → w)) → v)
となる。まとめる順番は、1.引数をまとめる、2.引数と関数をまとめる。としている。
(2)その時の環境すべてとは?
Schemeには大域変数が存在する。大域変数の保存先は環境である。
 (p.141 3.2.2章 図3.5 )
(p.141 3.2.2章 図3.5 )
図中の環境というのは、実態は単なる変数名と値のリストである。(→こんなの ((a b c) (1 2 3)) )
継続で必要な環境とは、この大域環境のことである。
(1)、(2) を合わせて、結局Schemeでは、F における y の継続とは、「合成関数 (z → w) +大域環境」ということになる。
説明しにくいので、継続の合成関数のことを"継続処理"、継続の大域環境のことを"継続環境"と呼ぶことにする。
継続=「継続処理(合成関数のこと) +継続環境(大域環境のこと)」
ここで1つ心配がある。継続環境の保存方法である。なぜなら、継続処理 (z → w) が継続環境(大域環境)を変更することがあるからである。y の終了時点での継続環境をどのように維持するか?
1. 継続環境のスナップショットを保存する。
2. 若しくは、継続環境を変更するときは、変更履歴を保存する。(必要に応じて、履歴を巻き戻すと、元の環境を再現できる)
SICPでは、2. の方法が採用されている。(p.257 analyze-assignment)
【2】
②継続の実装
ユーザの入力した式を、継続処理の列にバラして、その列を合成して1つの合成関数にまとめる。というのが実装の最終目標である。
なので、実装の中心的な処理は「2つの継続処理を1つに合成する」ということになる。3つ以上の継続の合成は、2つの合成を繰り返し適用すればよい。
で、2つの継続を合成する方法だが、例えば sin関数 と cos関数 の合成は簡単である。(sin (cos x)) しかし、(print "abc") と (sin 1.5) を合成するにはどうするか?
どんな継続でも、同じ手順で合成できるようにしたい。そのために工夫がいる。
(1) 式のλパック
最初に、式をλでパックすることを考える。これは、前の章4.1.7の評価器ですでに実施されていた。
式1 → 評価器(eval→analyze)→(λ(env) 1)→親Schemeで実行
amb 評価器では、このλパックを拡張して、引数に継続処理を渡すようにする。
式1 → 評価器(eval→analyze)→(λ(env s f) (s 1 f))→親Schemeで実行
s, f には継続処理が渡される。例えば s に w・z合成関数 、f にダミー関数、envに空リスト'()を渡して実行する。
((λ(env s f) (s 1 f)) '() (w・z合成関数) (dダミー関数)) ↓親Schemeで実行 ((w・z) 1 d)
というような感じ。引数に継続処理を渡すようにしても、継続処理 1→z→w つまり w(z(1))がうまく実行される。
(2) λパック2つを1つに合成する手順
例として、即値式を2つならべただけの複文を合成する場合を考える。
(begin 1
2)
継続処理列は
1 → 2
である。これを合成して
(1 → 2)
という合成関数を作りたいのである。具体的な作り方を見てみよう。
式1、式2を直接合成するのではなく、式のλパック、λ1、λ2 を合成する。
式1 のλパックは (λ(env s f) (s 1 f))である。図にしてみると、こんな感じになる。
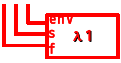 (λ(env s f)(s 1 f))
(λ(env s f)(s 1 f))
残念ながら、このままでは引数が多すぎてなにが何やらさっぱりである。なので、s の動きだけ追いかける。
式1のλパック
 (λ(s)(s 1))
(λ(s)(s 1))
同じく式2のλパック
 (λ(s)(s 2))
(λ(s)(s 2))
式1のλパックと式2のλパックの合成
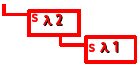 NG!
NG!
とできればいいのだが、これはNGである。λパックの関数形と継続処理 s の関数形が異なるので、直接接続できない。
λパックの関数形 → (λ(env s f) ...) p.255 14行目 継続処理sの関数形 → (λ(val f) ...) p.255 15行目
ややこしいので、s と val にだけ注目する。
λパックの関数形 → (λ(s) ...) 継続処理sの関数形 → (λ(val) ...)
λ2をλ1に接続するには、λ2を継続処理の形に変換して、それから接続すればよい。
(手順1)
まず、λ2に適当に s0 を与えて実行形にする。
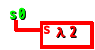 ((λ(s)(s 2)) s0)
((λ(s)(s 2)) s0)
(手順2)
これを λで囲って継続処理の形にする。これで、λ2パックを継続処理の形に変換できた。
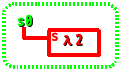 (λ(val)
(λ(val)
((λ(s)(s 2)) s0))
(手順3)
この継続処理をλ1に接続する。接続するというのは引数に渡すことである。
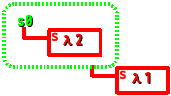 ((λ(s)(s 1))
((λ(s)(s 1))
(λ(val)
((λ(s)(s 2)) s0)))
(手順4)
最後に全体をλで囲ってλパックにする。
このとき、合成λパックの引数 s0 をλ2の継続処理に埋め込んでおく。そうしとけば、最後に実行されて具合がよい。(合成λパックの継続処理の列 λ1 → λ2 → s0 )
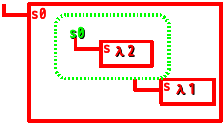 (λ(s0)
(λ(s0)
((λ(s)(s 1))
(λ(val)
((λ(s)(s 2)) s0))))
以上がλパック2個を合成して、λパック1個にする手順である。
まとめると合成λパックの基本形は
(λ(s0) ← 合成したλ
(λ1 ← 合成元のλ1
(λ(val) ← λ2を継続処理に変換するためのλ
(λ2 ← 合成元のλ2
s0)))) ← 合成λの継続処理
という形になる。
3個以上の合成は、2個の合成を繰り返し適用する。
この合成λパックが、元々の継続処理 1 → 2 を再現することを確かめよう。
確かめるために s0に適当な継続 (λ(val) 'success) を与えて、この合成λパックを実行してみよう。(λパックを実行するのは親Scheme)
(λ合成 (λ(val)'success))
↓
(λ1 (λ(val) (λ2 (λ(val)'success))))
↓
((λ(s)(s 1)) (λ(val) (λ2 (λ(val)'success))))
↓
((λ(val) (λ2 (λ(val)'success))) 1) ← ここで 1 実行 (引数は先に評価される)
↓
(λ2 (λ(val)'success))
↓
((λ(s)(s 2))(λ(val)'success))
↓
((λ(val)'success) 2) ← ここで 2 実行 (引数は先に評価される)
↓
'success ← 最後に s0 の本体実行
ちゃんと、1 → 2 → 'success という順番に実行されるのが確認できる。
(3) 継続環境の保存方法
継続環境の保存方法はどうなったか?これは継続処理 f に継続環境の巻き戻し処理を埋め込んでおけばよい。そうすれば 継続処理 f の実行時には巻き戻しが実行されて、継続環境が前の状態に復元する。p.257 analyze-assignment. なお、amb評価器では、巻き戻しは継続処理 f にのみ合成されている。継続処理 s で巻き戻しが必要になることがないので。
(4) 継続処理を合成する範囲
評価器は何処から何処まで継続処理の列を管理し合成したらいいのか?
トップレベルのカッコ始まり ( から カッコ終わり ) までである。本当は何処から何処まででもいいのだろうが、これは amb評価器の仕様である。(p.259 driver-loop の read 関数)
継続処理の管理開始 (...... ...... ...) 継続処理の管理終了 ↑ この間の継続処理は管理しない ↓ 継続処理の管理開始 (.......... .........) 継続処理の管理終了
トップレベルのカッコで囲まれた式というのは、
複文
(begin (a ...)
(b ...)
(c ...))
if文
(if ((d ...))
(e ...))
関数実行
(f 1 2)
などである。おのおの継続処理の列は、
複文の継続処理列は、式a → 式b →式c if文の継続処理列は、条件式 d → TRUE節 e 関数実行の継続処理列は、引数1 → 引数2 → 関数f
となる。amb評価器は、それぞれの継続処理列を合成する。
複文の継続処理列の合成 → p.256 analyze-sequence if文の継続処理列の合成 → p.256 analyze-if 関数実行の継続処理列の合成 → p258 get-args と p.257 analyze-application
p.256 analyze-sequence の作る合成関数は、上で見た基本形そのものである。
p.256 analyze-if、p258 get-args と p.257 analyze-applicationの作る合成関数は、基本形を少し変形したものになる。(s0の部分が変形される)
【3】
③ analyze-application の動作
では、非常にややこしい p.257 analyze-application の動作を考えよう。
まず、analyze-application の入力は、関数の実行形式、例えば (y 1 2)である。
(y 1 2)の継続処理列は
1 → 2 → y
である。analyze-application はこれを合成するのだが、2つの部分に分けて合成している。
① 引数の合成 (1 → 2)。 p.258 get-args
② 引数と関数の合成((1 → 2) → y)。 p.257 analyze-application
まず、① get-args から見ていく。
get-args の関数形は、
(get-args (aprocs env s f) ...) p.258 get-args
である。ややこしいので、env と f を無視すると
(get-args (aprocs s) ...)
となる。aprocs には (y 1 2) の引数の部分 (1 2) のλパックのリスト (λ1 λ2) が渡される。s0を適当な継続として、get-args の実行形は
(get-args '(λ1 λ2) s0)
となる。このまま実行を追いかけてみよう。 p.258 get-args を繰り返し適用して、
(get-args '(λ1 λ2) s0)
↓
(λ1
(λ(val1)
(get-args '(λ2) (λ(val2) (s0 (cons val1 val2))))))
↓
(λ1
(λ(val1)
(λ2
(λ(val3)
(get-args '() (λ(val4) ((λ(val2)(s0 (cons val1 val2))) (cons val3 val4))))))))
↓
(λ1
(λ(val1)
(λ2
(λ(val3)
((λ(val4) ((λ(val2) (s0 (cons val1 val2))) (cons val3 val4))) '()) )))))
となる。最終的に get-args は、
(get-args '(λ1 λ2) s0)の中身
(λ1
(λ(val1)
(λ2
(λ(val3)...s0...))))
という形に展開される。これは、λ1とλ2の合成形になっている。つまり、get-argsは、継続処理の引数部分 1 → 2 の合成関数になっている。ただし、基本形と違ってλ2の継続に s0 のほか val1、val2、val3、val4 が埋め込まれていてかなり複雑になっている。(そして動作が読みにくい)
実行させて、get-args が継続処理列 1 → 2 を再現し、さらに関数 y に引数リスト(1 2)をうまく渡せることを確認しよう。
λ1 を (λ(s)(s 1))、λ2 を (λ(s)(s 2)) として実行をすすめる。
((λ(s)(s 1))
(λ(val1)
((λ(s)(s 2))
(λ(val3)
((λ(val4) ((λ(val2) (s0 (cons val1 val2))) (cons val3 val4))) '()) )))))
↓
((λ(val1)
((λ(s)(s 2))
(λ(val3)
((λ(val4)((λ(val2)(s0(cons val1 val2)))(cons val3 val4)))'())))) 1) ← ここで 1 実行
↓
((λ (s) (s 2))
(λ(val3)
((λ(val4)((λ(val2)(s0(cons 1 val2)))(cons val3 val4)))'())))
↓
((λ(val3)
((λ(val4)((λ(val2)(s0(cons 1 val2)))(cons val3 val4)))'())) 2) ← ここで 2 実行
↓
((λ(val4)((λ(val2)(s0 (cons 1 val2)))(cons 2 val4))) '())
↓
((λ(val2)(s0 (cons 1 val2)))(cons 2 '()))
↓
((λ(val2)(s0 (cons 1 val2))) '(2))
↓
(s0 (cons 1 '(2)))
↓
(s0 '(1 2)) ← ここで s0 実行
まあ大方の予想通りとなっている。λ2の複雑な継続処理のおかげで、最後が単純な(s0) でなく、(s0 '(1 2)) となっている。 引数を実行したあとの継続処理は、関数 y の実行である。つまり、s0 には (exec y) 的なものが渡される。結局
(exec y '(1 2))
みたいな感じになって、めでたく (y 1 2) が実行されるはずである。
最後に、この引数と 関数 y を合成する部分を確認しよう。 といっても、get-args に比べるととても簡単である。
これを処理するのは ② p.257 analyze-application である。
analyze-application の返すλパックを見てみよう。例によって、f と env は無視して、 s と val だけ追いかける。
(λ(s0)
(pproc
(λ (val1)
(get-args aprocs
(λ (val2) (execute-application val1 val2 s0))))))
こんな形である。pproc には、(λ(s) (s (lookup-variable-value 'y))))が渡される。(p.255 analyze-variableの結果) 。 aprocs は上で見たように、'(λ1 λ2) というリストが渡される。なので
(λ(s0)
((λ(s)(s (lookup-variable-value 'y)))
(λ (val1)
(get-args '(λ1 λ2) ← get-args は(1 → 2)の合成λパック
(λ (val2) (execute-application val1 val2 s0))))))
となる。これは、((1 → 2) → y)というλパックの合成になっている。基本形と違って s0 の埋め込み部分に execute-application...という処理が追加されている。追加処理の効果を確かめるため、実行を追いかけよう。
と、その前に適当に y を定義しておく。
(define (y a b) (+ a b))
これを、amb評価器に渡すと、p.257 analyze-definition → p.256 analyze-lambda → p223 make-procedure という処理を経て、大域環境に (y ('procedure (a b) (+ a b)))というエントリが追加される。
で、元に戻って実行を進める。見やすくするために、lookup-variable-value は lookup、execute-application は exec と表記する。
(λ(s0)
((λ(s)(s (lookup 'y))) ← lookup は lookup-variable-value のこと
(λ(val1)
(get-args '(λ1 λ2)
(λ(val2) (exec val1 val2 s0)))))) ← exec は execute-application のこと
↓
((λ(s)(s (lookup 'y)))
(λ(val1)
(get-args '(λ1 λ2)
(λ(val2) (exec val1 val2 s0)))))
↓
((λ(val1)
(get-args '(λ1 λ2)
(λ(val2) (exec val1 val2 s0)))) (lookup 'y)) ← ここで (lookup 'y) の実行
↓
((λ(val1)
(get-args '(λ1 λ2)
(λ(val2) (exec val1 val2 s0)))) '('procedure (a b) (+ a b)) )
↓
(get-args '(λ1 λ2)
(λ(val2) (exec '('procedure (a b) (+ a b)) val2 s0)))
↓
((λ(val2) (exec '('procedure (a b) (+ a b)) val2 s0) '(1 2)) ← get-args の実行は上で追いかけたとおり。
↓
(exec '('procedure (a b) (+ a b)) '(1 2) s0)
となって最終的に、(exec y '(1 2)) 的なものが実行される。
以上。